
AcuBliss is a booking and scheduling platform built with a lean engineering team. Like many bootstrapped companies, they spent a long time operating without deep backend visibility. When something slowed down, someone had to stop what they were doing and go hunt for the problem manually.
Digging through logs, reproducing issues locally, and eliminating possibilities one by one becomes a hidden tax on engineering teams.
“Without the level of visibility that Scout provides, you’re flying blind and resolution takes much longer.” — Graham Quigley, CEO, AcuBliss
Every production issue pulls engineers away from shipping. Every slow page users experience before the root cause is identified affects conversions, bookings, or trust. For small teams, those costs compound quickly because the same engineers building the product are also responsible for diagnosing production problems. There’s no dedicated operations team absorbing the overhead.
The right tool for the right layer
AcuBliss already used PostHog for product analytics and session recording. It helped the team understand what users were doing inside the product. What it didn’t provide was visibility into why requests were slowing down.
“PostHog is invaluable to us on the product analytics and session recording side, but it doesn’t touch what’s happening at the database layer.” — Graham Quigley, CEO, AcuBliss
The team also evaluated Datadog. It solved the backend visibility problem, but the pricing and operational complexity didn’t make sense for a lean engineering organization.
Scout fit the middle ground: SQL-level visibility, request tracing, and N+1 query detection without requiring a dedicated platform engineering function to manage it. Instead of digging through layers of dashboards, engineers could go directly from “this endpoint feels slow” to the exact query or code path responsible.
What it looks like when it works
In early 2025, AcuBliss started seeing performance degradation across parts of the platform. Response times on several booking-related workflows began creeping upward.
Using Scout, the team connected the slowdown to specific database queries and isolated the issue quickly enough to ship a fix before it became a larger customer problem.
Without that visibility, the same investigation would have started with vague symptoms, log hunting, and hours of debugging across multiple systems before anyone had confidence they’d found the real issue.
“Scout gave us the visibility we needed to connect what was happening on the surface to the exact database queries behind it.” — Graham Quigley, CEO, AcuBliss
Today, the team uses Scout both reactively and proactively: monitoring production issues as they happen, and reviewing performance trends regularly to catch inefficiencies before they turn into incidents.
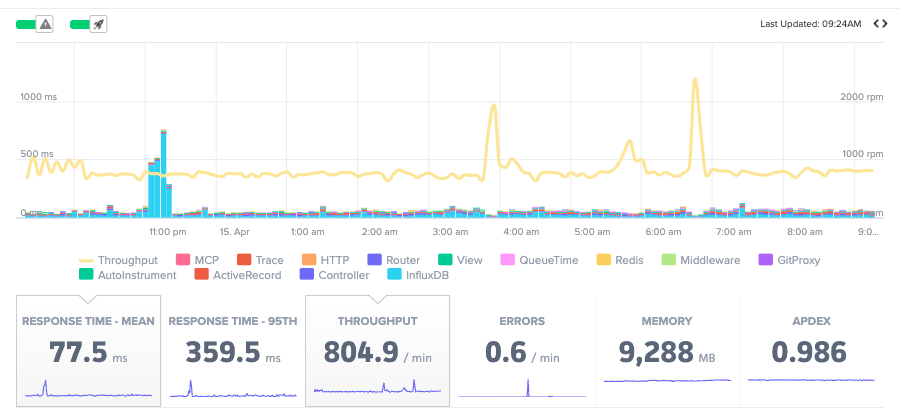
Built for how small teams work now
Most small engineering teams are already using AI coding assistants as part of their daily workflow. Scout extends directly into those workflows through its MCP server and CLI.
Developers using Claude Code, Cursor, or other AI tools can pull production context directly into debugging sessions: slow endpoints, recent traces, N+1 queries, database bottlenecks, and error details.
AcuBliss uses Claude Code with Scout’s MCP integration. When Scout surfaces a slow endpoint, engineers ask Claude Code to investigate. It calls the Scout MCP directly, pulls the slow traces, and starts looking for patterns.
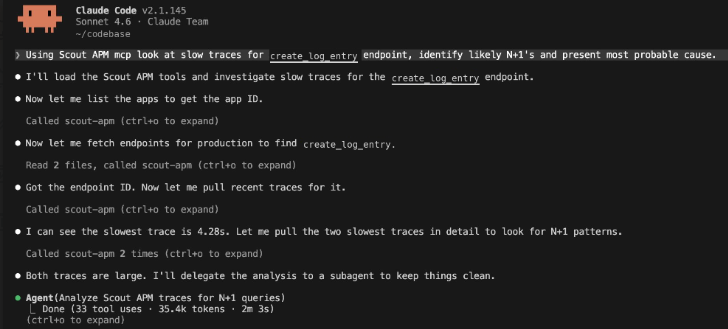
Here’s what that looks like on a real endpoint:
Endpoint: create_log_entry
Avg response: 637ms | P95: 646ms | Worst trace: 4.28s with 418 SQL queries
The query count scales linearly with data size, a classic N+1 signature. Claude Code surfaces the confirmed patterns ranked by impact:
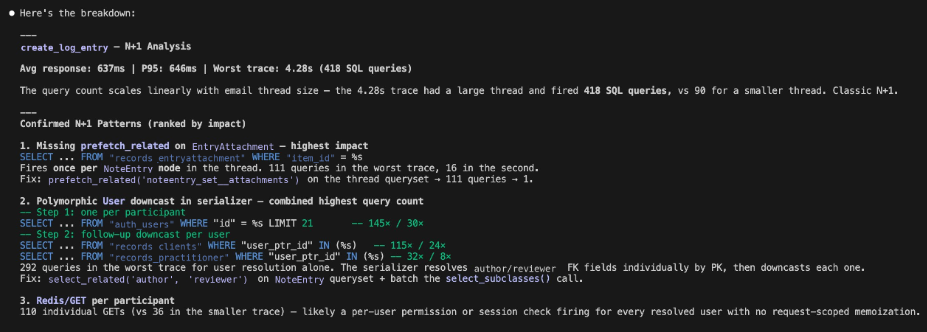
| Pattern | Queries (worst trace) | Fix |
|---|---|---|
Missing prefetch_related on EntryAttachment |
111 | prefetch_related('noteentry_set__attachments') |
| Polymorphic user downcast in serializer | 292 | select_related('author', 'reviewer') + batch select_subclasses() |
| Redis/GET per participant | 110 | Request-scoped memoization |

Root cause: the NoteEntry serializer resolves participants and attachments lazily, firing individually per object instead of in batch. These three patterns together account for around 400 of the 418 queries in the worst trace. Claude Code points directly to core/records/viewsets/items.py as the file to fix.
That’s the whole loop in under 3 minutes. Instead of an engineer digging through logs chasing a vague performance complaint, Claude Code and Scout together identify the cause, rank the fixes by impact, and point to the exact code.
The math
Scout’s value isn’t really measured in dashboards or traces. It’s measured in engineering time recovered.
A single production issue resolved in minutes instead of hours can justify months of the subscription cost. But the bigger value comes from eliminating the constant debugging overhead that slows small teams down over time. The slow pages users never notice. The Friday afternoons not spent chasing intermittent issues. The confidence to ship changes knowing problems can be isolated quickly if something regresses.
“Scout covers a layer of our stack that nothing else touches for us. It’s filling a gap that really matters when it counts.” — Graham Quigley, CEO, AcuBliss
Flying blind is a choice. It just rarely feels like one until you stop.
Want to see what Scout finds in your app? Start a free trial. No credit card required, monitoring in minutes.